

A origem da cifra genética, o problema mais intrigante na biologia
http://elohim.heavenforum.org/t224-a-origem-da-cifra-genetica-o-problema-mais-intrigante-na-biologia
Uma revisão do livro de Paul Davies , o quinto milagre ( the fifth miracle ) , sobre o código genético. A partir de página 105:
Eu descrevi a vida como um acordo firmado entre os ácidos nucleicos e as proteínas. No entanto, estas moléculas tem domínios químicos muito diferentes ; na verdade, elas são mal em condições de falar. Isto é mais claramente refletido na aritmética de transferência de informação. Os dados necessários para montar proteínas são armazenados no DNA utilizando o alfabeto de quatro letras A, G, C, T. Por outro lado, as proteínas são feitas de vinte tipos diferentes de aminoácidos. Obviamente vinte em quatro não funciona. Então, como ácidos nucleicos e proteínas comunicam?
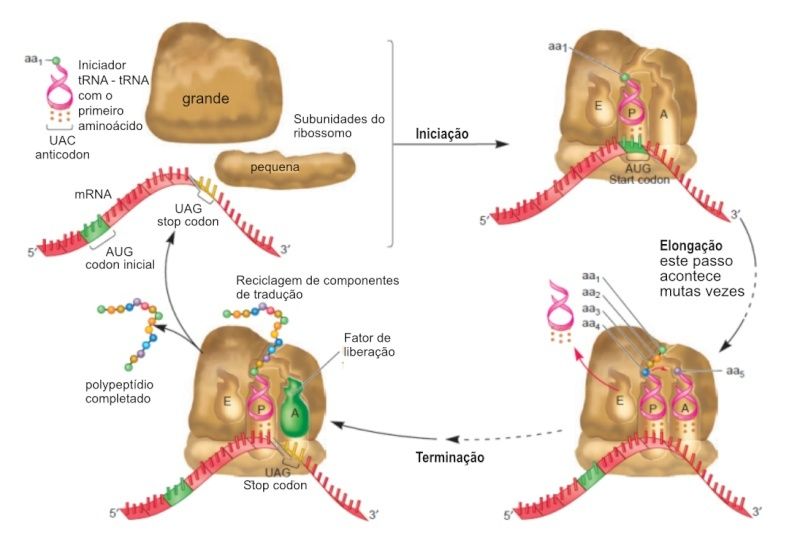
Visão geral dos estágios de tradução. A fase de iniciação envolve a montagem das subunidades ribossomais, mRNA, e o tRNA iniciador transportando o primeiro aminoácido. Durante o alongamento, o ribossoma desliza ao longo do mRNA e sintetiza uma cadeia de polipeptídio. A tradução termina quando um códon de terminação é atingido e o polipeptídio é libertado do ribossoma.
A vida na terra descobriu uma solução elegante para esse descompasso numérico empacotando as bases em tripletos.
Como a vida na terra poderia ter descoberto um mecanismo do qual a vida depende?
Quatro bases podem ser arranjados em sessenta e quatro permutações diferentes de três, e vinte cabem em sessenta e quatro, com algum espaço de sobra para redundância e pontuação. A sequência de degraus da escada de DNA determina, assim, três por três, a sequência exata de aminoácidos nas proteínas. Para traduzir a partir das sessenta e quatro tripletos ( 4 x 4 x 4 = 64 ) para os vinte aminoácidos significa a atribuição de cada tripleto (denominado um codon) um aminoácido correspondente. Esta tarefa é chamada o código genético. A idéia de que a vida usa uma cifra foi sugerida pela primeira vez no início dos anos 1950 por George Gamow, o mesmo físico que propôs a teoria do big-bang moderno do universo. Como em todas as traduções, deve haver alguém, ou algo, que é bilíngüe, neste caso a tornar as instruções codificadas em linguagem dos ácidos nucleicos em um resultado escrito em linguagem de aminoácidos. Do que tenho explicado, deve ser aparente que esta etapa de tradução fundamental ocorre em organismos vivos, quando os aminoácidos apropriados estão ligados para as respectivas moléculas de tRNA antes do processo da montagem das proteínas . Esta fixação é realizada por um grupo de enzimas inteligentes ( Inteligência é algo que costumamos atribuir a alguém que é inteligente ) que reconhecem ambas as sequências de mRNA e os diferentes aminoácidos, e casar-los em conformidade com a designação direita.
O reconhecimento deve ser pré-programado. Do mesmo modo, como um tradutor deve aprender duas línguas, a fim de ser capaz de atribuir uma palavra escrita em português, por exemplo, para o símbolo escrita em chinês com o mesmo significado. Deve haver um acordo comum prévio de significado antes que o processo de tradução pode começar. Como por exemplo, a palavra tradutor, está escrita 翻譯 者 em chinês tradicional. Peça a alguém que não fala chinês, para traduzir a palavra tradutor em chinês. Ele tem cerca de 3500 símbolos diferentes para escolher. Na "linguagem dos aminoácidos", existem 20 aminoácidos diferentes para escolher. O tradutor deve saber tanto a palavra tradutor em Inglês e em chinês, e conhecer os dois alfabetos escritos, anteriormente, para conseguir fazer a atribuição. Apenas os processos mentais são capazes de fazer isso. O acaso é simplesmente uma causa impotente.
William Dembsky:
http://www.discovery.org/a/1256
O problema é que a natureza tem muitas opções e sem projeto não poderia encontrar em função de todas essas opções. O problema é que os mecanismos naturais são muito inespecíficos para determinar qualquer resultado em particular. Os processos naturais poderiam teoricamente formar uma proteína, mas também são compatíveis com a formação de uma multiplicidade de outras montagens moleculares, a maioria dos quais não têm qualquer significado biológico. A natureza permite-lhes total liberdade de arranjo. No entanto, é precisamente essa liberdade que faz a natureza incapaz de explicar os resultados especificados de pequena probabilidade. A natureza, neste caso, ao invés de ter a intenção de fazer apenas uma coisa, é aberta a fazer uma série, alias qualquer coisa sem objetivo. No entanto, quando uma dessas coisas é um evento especificado altamente improvável, projeto se torna mais atraente, é a melhor inferência. A navalha de Occam também resume-se a um argumento da ignorância: na ausência de uma informação melhor, você usa uma heurística para aceitar uma hipótese sobre a outra.
O código genético, com algumas variações menores recentemente descoberto, é comum a todas as formas de vida conhecidas. Que o código é universal é extremamente significativo, pois sugere que ele foi usado pelo ancestral comum de toda a vida, e é robusto o suficiente para ter sobrevivido através de bilhões de anos de evolução. Perguntas não faltam. Como é que um sistema tão complicado e específico como o código genético surgiu em primeiro lugar? Por que, dos 10 possíveis códigos baseados em trigêmeos, a natureza escolheu aquele com uso universal? Poderia um código diferente funcionar também? Se existe vida em Marte, ela terá o mesmo código genético como a vida na terra? Podemos imaginar a vida não codificada, na qual as moléculas interdependentes lidariam diretamente umas com as outras com base em suas afinidades químicas sozinho? O biólogo britânico John Maynard Smith descreveu a origem do código como o problema mais desconcertante na biologia evolutiva. Com o colaborador Eörs Szathmáry ele escreve: "A maquinaria de tradução existente é ao mesmo tempo tão complexa, tão universal, e tão essencial que é difícil ver como ela poderia ter entrada em vigor, ou como a vida poderia ter existida sem ela." Para se ter uma ideia de por que o código é um enigma, tem que considerar se há algo de especial em relação aos números envolvidos. Por que a vida usa vinte aminoácidos e quatro bases de nucleotídeos? Seria muito mais simples para empregar, digamos, dezesseis aminoácidos e empacotar as quatro bases em parelhas, em vez de trigêmeos. Ainda mais fácil seria ter apenas duas bases e usar um código binário, como um computador. Se um sistema mais simples tivesse evoluído, é difícil ver como o código tripleto mais complicado jamais iria surgir. A resposta poderia ser um caso de "Era uma boa ideia no momento." Uma boa ideia de quem? Se o código evoluiu em um estágio muito cedo na história de vida, talvez até mesmo durante a fase de pré-biótica, os números quatro e vinte podem ter sido a melhor maneira de proceder por razões químicas relevantes nessa fase. A vida simplesmente ficou presa com esses números, posteriormente, quando o seu propósito original se perdeu. Ou talvez o uso de vinte e quatro é a melhor forma de fazê-lo. Há uma vantagem na vida de empregar muitas variedades de aminoácido, porque eles podem ser amarrados juntos em mais maneiras de oferecer uma seleção mais ampla de proteínas. Mas há também um preço: com o aumento do número de aminoácidos, o risco de erros de tradução cresce. Com muitos aminoácidos ao redor, haveria uma maior probabilidade de que a errada seria presa à cadeia de proteínas. Então, talvez vinte é um bom compromisso. Reações químicas aleatórias têm conhecimento para chegar a uma conclusão ideal, ou um "bom compromisso"?
Um problema ainda mais difícil diz respeito às atribuições, ou seja codificação, quais codons trigêmeos codificam quais ácidos aminados ? Como essas designações aconteceram? Porque bases de ácido nucleico e aminoácidos não reconhecem uns aos outros diretamente, mas tem que estar separados por intermediários químicos, não há nenhuma razão óbvia por particulares trigêmeos parear com determinados aminoácidos. Outros traduções são concebíveis. Instruções codificadas são uma boa ideia, mas o código real parece ser bastante arbitrário. Talvez seja simplesmente um acidente congelado, uma escolha aleatória que apenas trancou em si mesmo, sem nenhum significado mais profundo. (!!! dá para acreditar numa explicação dessa ?? )
Esse acidente congelado significa, que a boa sorte teria ganho na loteria o prêmio máximo entre 1,5 × 10^84 códigos genéticos possíveis . Isto é o número de átomos em todo o universo. Isso coloca qualquer possibilidade real de chance conseguir o feito fora de questão. O tempo máximo disponível para que originam foi estimada em 6.3 x 10 ^ 15 segundos. A seleção natural teria que avaliar cerca de 10 ^ 55 códigos por segundo para encontrar o que é o código universal. Simplificando, a seleção natural não tem o tempo necessário para encontrar o código genético universal. Usando a lei de Borel, esta possibilidade fica no reino do impossivel. 1
Por outro lado, pode haver alguma razão sutil porque este código especial funciona melhor. Se um código teve a vantagem sobre algum outro, então a evolução iria favorece-lo.
O problema é mais uma vez, que a evolução não poderia estar em ação neste momento e estágio de coisas, uma vez que a evolução só funciona em cima de replicação. Replicação depende da máquina em questão. Belo problema ovo - galinha.
, E, por um processo de refinamento sucessivo, um código ótimo seria alcançado. Parece razoável.
Parece razoável? Para mim, parece IRRACIONALIDADE TOTAL, ao extremo. Então, se é aleatório, um processo de acaso de produtos quimicos não-inteligentes, esses têm um objetivo pré-estabelecido para alcançar um código ideal? E mesmo se fosse esse o caso, que bom seria sem a maquinaria de tradução, o ribossomo, totalmente configurado , já no lugar, para fazer o seu trabalho de tradução ?
Mas esta teoria não é sem problemas também. A evolução darwiniana funciona em passos incrementais, acumulando pequenas vantagens sobre muitas gerações. No caso do código, isto não é possível. Mudando mesmo uma única atribuição normalmente prova ser letal, porque altera não apenas um, mas todo um conjunto de proteínas. Entre estes estão as proteínas que ativam e facilitam o processo de tradução. Assim, uma alteração no código levaria a uma reação catastrófica de erros que iria destruir todo o processo. Para se ter uma tradução exata, a célula deve primeiro traduzir com precisão. Esta conclusão parece paradoxal. Uma possível solução tem sido sugerida por Carl Woese. Ele acha que as atribuições de código e o mecanismo de tradução evoluíram juntos. Inicialmente havia apenas um código áspero-e-pronto, e o processo de tradução era muito desleixado. Nesta fase inicial, o que é provável que tenha envolvido menos do que o presente complemento de vinte aminoácidos, organismos tiveram que se contentar com enzimas muito ineficientes: a vida de enzimas altamente específicas e refinadas usadas hoje ainda não tinha evoluído. Obviamente algumas atribuições de codificação se demonstraria melhor do que outros, e qualquer organismo que empregue as atribuições passíveis de erros menores para codificar suas enzimas mais importantes seria o vencedor. Desde quando a matéria morta tem o desejo intrínseca de se tornar viva, e de ganhar? Estaria replicando de forma mais precisa, e no processo os seus acordos de codificação poderiam predominar entre as células filhas. Neste contexto, uma "melhor" atribuição de codificação significaria mais robustez, de modo que, se houver um erro de tradução, o mesmo aminoácido, não obstante, ser feito, isto é, haveria ambiguidade suficiente para que o erro não faria muita diferença. Ou, no caso do erro causar um aminoácido diferente ser feito, seria um parente próximo do que se pretendia, e a proteína resultante faria o trabalho quase tão bem. Refinamentos sucessivas deste processo podem, então, levar ao código universal visto hoje como um retrato-vindo gradualmente em foco.
Agora isto que é uma grande palestra de como fazer pseudo-ciência, e atribuir ao acaso o poder criativo que ele não tem.
O código pode ter uma explicação mais profunda completamente. Se uma tabela de atribuições de codificação é redigido, ele pode ser analisado matematicamente para ver se existem quaisquer padrões escondidos. Peter Jarvis e seus colegas da Universidade da Tasmânia afirmam que o código universal esconde sequências abstratas semelhantes aos níveis de energia dos núcleos atômicos, e pode até envolver uma propriedade sutil das partículas subatômicas chamadas supersimetria. Estas correspondências matemáticas podem ser mera coincidência ( será ? ), ou eles podem apontar para alguma ligação subjacente entre a física das moléculas envolvidas e da organização do código. Tenho submetido ao leitor os aspectos técnicos do código genético para apresentar o conceito geral que vai direto ao coração do mistério da vida. Qualquer código escrito é meramente um amontoado de dados inúteis a menos que um intérprete ou uma chave está disponível. A mensagem codificada é apenas tão boa quanto o contexto em que ela é colocada em uso. Ou seja, tem que significar algo. No capítulo 2, eu tirei a distinção entre a informação sintática e semântica. Por conta própria, os dados genéticos são mera sintaxe. A utilidade notável de informação genética codificada deriva do fato de que os aminoácidos "compreendem" ele. A informação distribuída ao longo de uma cadeia de DNA é biologicamente relevante. Em linguagem de informática, os dados genéticos são dados semânticos. Para uma perspectiva clara sobre este ponto, considere a maneira em que as quatro bases A, G, C e T são dispostas no DNA. Como explicado, estas sequências são como letras em um alfabeto, e as letras podem soletrar, em código, as instruções para fazer proteínas. Uma sequência diferente de letras quase certamente seria biologicamente inútil. Apenas uma pequena fração de todas as sequências possíveis explicita uma mensagem biologicamente significativa, da mesma forma que somente certas sequências muito especiais de letras e palavras constituem um livro significativo. Outra forma de expressar isso é dizer que os genes e proteínas requerem extremamente elevados graus de especificidade em sua estrutura. Como afirmei na minha lista de propriedades no capítulo 1, os organismos vivos não são misteriosos por causa da complexidade em si, mas pela sua complexidade firmemente especificada. Para compreender plenamente como a vida surgiu da matéria inorgânica, precisamos saber não apenas como informação biológica foi concentrada, mas também como informação biologicamente útil veio a ser especificada, uma vez que o meio a partir do qual o primeiro organismo emergiu foi, presumivelmente, apenas uma mistura aleatória de blocos de construção moleculares. Em suma, como é que informações significativas surgem espontaneamente do lixo incoerente?
Comecei esta secção, sublinhando a natureza dual das biomoléculas: elas podem ser tanto hardware , formas especiais e tridimensionais, e software. O código genético mostra o quão importante é o aspecto informativo de biomoléculas. O trabalho de explicar a origem da vida vai além de encontrar uma via química plausível de uma sopa primordial. Precisamos saber, conceitualmente, como hardware simples pode dar origem a software.
Para o proponente de design, a resposta é evidente....
Este argumento por si só destrói o naturalismo. E pior que um knock out the Mike Tyson, haha.....
https://en.wikipedia.org/wiki/Genetic_code
http://elohim.heavenforum.org/t224-a-origem-da-cifra-genetica-o-problema-mais-intrigante-na-biologia
Uma revisão do livro de Paul Davies , o quinto milagre ( the fifth miracle ) , sobre o código genético. A partir de página 105:
Eu descrevi a vida como um acordo firmado entre os ácidos nucleicos e as proteínas. No entanto, estas moléculas tem domínios químicos muito diferentes ; na verdade, elas são mal em condições de falar. Isto é mais claramente refletido na aritmética de transferência de informação. Os dados necessários para montar proteínas são armazenados no DNA utilizando o alfabeto de quatro letras A, G, C, T. Por outro lado, as proteínas são feitas de vinte tipos diferentes de aminoácidos. Obviamente vinte em quatro não funciona. Então, como ácidos nucleicos e proteínas comunicam?
Visão geral dos estágios de tradução. A fase de iniciação envolve a montagem das subunidades ribossomais, mRNA, e o tRNA iniciador transportando o primeiro aminoácido. Durante o alongamento, o ribossoma desliza ao longo do mRNA e sintetiza uma cadeia de polipeptídio. A tradução termina quando um códon de terminação é atingido e o polipeptídio é libertado do ribossoma.
A vida na terra descobriu uma solução elegante para esse descompasso numérico empacotando as bases em tripletos.
Como a vida na terra poderia ter descoberto um mecanismo do qual a vida depende?
Quatro bases podem ser arranjados em sessenta e quatro permutações diferentes de três, e vinte cabem em sessenta e quatro, com algum espaço de sobra para redundância e pontuação. A sequência de degraus da escada de DNA determina, assim, três por três, a sequência exata de aminoácidos nas proteínas. Para traduzir a partir das sessenta e quatro tripletos ( 4 x 4 x 4 = 64 ) para os vinte aminoácidos significa a atribuição de cada tripleto (denominado um codon) um aminoácido correspondente. Esta tarefa é chamada o código genético. A idéia de que a vida usa uma cifra foi sugerida pela primeira vez no início dos anos 1950 por George Gamow, o mesmo físico que propôs a teoria do big-bang moderno do universo. Como em todas as traduções, deve haver alguém, ou algo, que é bilíngüe, neste caso a tornar as instruções codificadas em linguagem dos ácidos nucleicos em um resultado escrito em linguagem de aminoácidos. Do que tenho explicado, deve ser aparente que esta etapa de tradução fundamental ocorre em organismos vivos, quando os aminoácidos apropriados estão ligados para as respectivas moléculas de tRNA antes do processo da montagem das proteínas . Esta fixação é realizada por um grupo de enzimas inteligentes ( Inteligência é algo que costumamos atribuir a alguém que é inteligente ) que reconhecem ambas as sequências de mRNA e os diferentes aminoácidos, e casar-los em conformidade com a designação direita.
O reconhecimento deve ser pré-programado. Do mesmo modo, como um tradutor deve aprender duas línguas, a fim de ser capaz de atribuir uma palavra escrita em português, por exemplo, para o símbolo escrita em chinês com o mesmo significado. Deve haver um acordo comum prévio de significado antes que o processo de tradução pode começar. Como por exemplo, a palavra tradutor, está escrita 翻譯 者 em chinês tradicional. Peça a alguém que não fala chinês, para traduzir a palavra tradutor em chinês. Ele tem cerca de 3500 símbolos diferentes para escolher. Na "linguagem dos aminoácidos", existem 20 aminoácidos diferentes para escolher. O tradutor deve saber tanto a palavra tradutor em Inglês e em chinês, e conhecer os dois alfabetos escritos, anteriormente, para conseguir fazer a atribuição. Apenas os processos mentais são capazes de fazer isso. O acaso é simplesmente uma causa impotente.
William Dembsky:
http://www.discovery.org/a/1256
O problema é que a natureza tem muitas opções e sem projeto não poderia encontrar em função de todas essas opções. O problema é que os mecanismos naturais são muito inespecíficos para determinar qualquer resultado em particular. Os processos naturais poderiam teoricamente formar uma proteína, mas também são compatíveis com a formação de uma multiplicidade de outras montagens moleculares, a maioria dos quais não têm qualquer significado biológico. A natureza permite-lhes total liberdade de arranjo. No entanto, é precisamente essa liberdade que faz a natureza incapaz de explicar os resultados especificados de pequena probabilidade. A natureza, neste caso, ao invés de ter a intenção de fazer apenas uma coisa, é aberta a fazer uma série, alias qualquer coisa sem objetivo. No entanto, quando uma dessas coisas é um evento especificado altamente improvável, projeto se torna mais atraente, é a melhor inferência. A navalha de Occam também resume-se a um argumento da ignorância: na ausência de uma informação melhor, você usa uma heurística para aceitar uma hipótese sobre a outra.
O código genético, com algumas variações menores recentemente descoberto, é comum a todas as formas de vida conhecidas. Que o código é universal é extremamente significativo, pois sugere que ele foi usado pelo ancestral comum de toda a vida, e é robusto o suficiente para ter sobrevivido através de bilhões de anos de evolução. Perguntas não faltam. Como é que um sistema tão complicado e específico como o código genético surgiu em primeiro lugar? Por que, dos 10 possíveis códigos baseados em trigêmeos, a natureza escolheu aquele com uso universal? Poderia um código diferente funcionar também? Se existe vida em Marte, ela terá o mesmo código genético como a vida na terra? Podemos imaginar a vida não codificada, na qual as moléculas interdependentes lidariam diretamente umas com as outras com base em suas afinidades químicas sozinho? O biólogo britânico John Maynard Smith descreveu a origem do código como o problema mais desconcertante na biologia evolutiva. Com o colaborador Eörs Szathmáry ele escreve: "A maquinaria de tradução existente é ao mesmo tempo tão complexa, tão universal, e tão essencial que é difícil ver como ela poderia ter entrada em vigor, ou como a vida poderia ter existida sem ela." Para se ter uma ideia de por que o código é um enigma, tem que considerar se há algo de especial em relação aos números envolvidos. Por que a vida usa vinte aminoácidos e quatro bases de nucleotídeos? Seria muito mais simples para empregar, digamos, dezesseis aminoácidos e empacotar as quatro bases em parelhas, em vez de trigêmeos. Ainda mais fácil seria ter apenas duas bases e usar um código binário, como um computador. Se um sistema mais simples tivesse evoluído, é difícil ver como o código tripleto mais complicado jamais iria surgir. A resposta poderia ser um caso de "Era uma boa ideia no momento." Uma boa ideia de quem? Se o código evoluiu em um estágio muito cedo na história de vida, talvez até mesmo durante a fase de pré-biótica, os números quatro e vinte podem ter sido a melhor maneira de proceder por razões químicas relevantes nessa fase. A vida simplesmente ficou presa com esses números, posteriormente, quando o seu propósito original se perdeu. Ou talvez o uso de vinte e quatro é a melhor forma de fazê-lo. Há uma vantagem na vida de empregar muitas variedades de aminoácido, porque eles podem ser amarrados juntos em mais maneiras de oferecer uma seleção mais ampla de proteínas. Mas há também um preço: com o aumento do número de aminoácidos, o risco de erros de tradução cresce. Com muitos aminoácidos ao redor, haveria uma maior probabilidade de que a errada seria presa à cadeia de proteínas. Então, talvez vinte é um bom compromisso. Reações químicas aleatórias têm conhecimento para chegar a uma conclusão ideal, ou um "bom compromisso"?
Um problema ainda mais difícil diz respeito às atribuições, ou seja codificação, quais codons trigêmeos codificam quais ácidos aminados ? Como essas designações aconteceram? Porque bases de ácido nucleico e aminoácidos não reconhecem uns aos outros diretamente, mas tem que estar separados por intermediários químicos, não há nenhuma razão óbvia por particulares trigêmeos parear com determinados aminoácidos. Outros traduções são concebíveis. Instruções codificadas são uma boa ideia, mas o código real parece ser bastante arbitrário. Talvez seja simplesmente um acidente congelado, uma escolha aleatória que apenas trancou em si mesmo, sem nenhum significado mais profundo. (!!! dá para acreditar numa explicação dessa ?? )
Esse acidente congelado significa, que a boa sorte teria ganho na loteria o prêmio máximo entre 1,5 × 10^84 códigos genéticos possíveis . Isto é o número de átomos em todo o universo. Isso coloca qualquer possibilidade real de chance conseguir o feito fora de questão. O tempo máximo disponível para que originam foi estimada em 6.3 x 10 ^ 15 segundos. A seleção natural teria que avaliar cerca de 10 ^ 55 códigos por segundo para encontrar o que é o código universal. Simplificando, a seleção natural não tem o tempo necessário para encontrar o código genético universal. Usando a lei de Borel, esta possibilidade fica no reino do impossivel. 1
Por outro lado, pode haver alguma razão sutil porque este código especial funciona melhor. Se um código teve a vantagem sobre algum outro, então a evolução iria favorece-lo.
O problema é mais uma vez, que a evolução não poderia estar em ação neste momento e estágio de coisas, uma vez que a evolução só funciona em cima de replicação. Replicação depende da máquina em questão. Belo problema ovo - galinha.
, E, por um processo de refinamento sucessivo, um código ótimo seria alcançado. Parece razoável.
Parece razoável? Para mim, parece IRRACIONALIDADE TOTAL, ao extremo. Então, se é aleatório, um processo de acaso de produtos quimicos não-inteligentes, esses têm um objetivo pré-estabelecido para alcançar um código ideal? E mesmo se fosse esse o caso, que bom seria sem a maquinaria de tradução, o ribossomo, totalmente configurado , já no lugar, para fazer o seu trabalho de tradução ?
Mas esta teoria não é sem problemas também. A evolução darwiniana funciona em passos incrementais, acumulando pequenas vantagens sobre muitas gerações. No caso do código, isto não é possível. Mudando mesmo uma única atribuição normalmente prova ser letal, porque altera não apenas um, mas todo um conjunto de proteínas. Entre estes estão as proteínas que ativam e facilitam o processo de tradução. Assim, uma alteração no código levaria a uma reação catastrófica de erros que iria destruir todo o processo. Para se ter uma tradução exata, a célula deve primeiro traduzir com precisão. Esta conclusão parece paradoxal. Uma possível solução tem sido sugerida por Carl Woese. Ele acha que as atribuições de código e o mecanismo de tradução evoluíram juntos. Inicialmente havia apenas um código áspero-e-pronto, e o processo de tradução era muito desleixado. Nesta fase inicial, o que é provável que tenha envolvido menos do que o presente complemento de vinte aminoácidos, organismos tiveram que se contentar com enzimas muito ineficientes: a vida de enzimas altamente específicas e refinadas usadas hoje ainda não tinha evoluído. Obviamente algumas atribuições de codificação se demonstraria melhor do que outros, e qualquer organismo que empregue as atribuições passíveis de erros menores para codificar suas enzimas mais importantes seria o vencedor. Desde quando a matéria morta tem o desejo intrínseca de se tornar viva, e de ganhar? Estaria replicando de forma mais precisa, e no processo os seus acordos de codificação poderiam predominar entre as células filhas. Neste contexto, uma "melhor" atribuição de codificação significaria mais robustez, de modo que, se houver um erro de tradução, o mesmo aminoácido, não obstante, ser feito, isto é, haveria ambiguidade suficiente para que o erro não faria muita diferença. Ou, no caso do erro causar um aminoácido diferente ser feito, seria um parente próximo do que se pretendia, e a proteína resultante faria o trabalho quase tão bem. Refinamentos sucessivas deste processo podem, então, levar ao código universal visto hoje como um retrato-vindo gradualmente em foco.
Agora isto que é uma grande palestra de como fazer pseudo-ciência, e atribuir ao acaso o poder criativo que ele não tem.
O código pode ter uma explicação mais profunda completamente. Se uma tabela de atribuições de codificação é redigido, ele pode ser analisado matematicamente para ver se existem quaisquer padrões escondidos. Peter Jarvis e seus colegas da Universidade da Tasmânia afirmam que o código universal esconde sequências abstratas semelhantes aos níveis de energia dos núcleos atômicos, e pode até envolver uma propriedade sutil das partículas subatômicas chamadas supersimetria. Estas correspondências matemáticas podem ser mera coincidência ( será ? ), ou eles podem apontar para alguma ligação subjacente entre a física das moléculas envolvidas e da organização do código. Tenho submetido ao leitor os aspectos técnicos do código genético para apresentar o conceito geral que vai direto ao coração do mistério da vida. Qualquer código escrito é meramente um amontoado de dados inúteis a menos que um intérprete ou uma chave está disponível. A mensagem codificada é apenas tão boa quanto o contexto em que ela é colocada em uso. Ou seja, tem que significar algo. No capítulo 2, eu tirei a distinção entre a informação sintática e semântica. Por conta própria, os dados genéticos são mera sintaxe. A utilidade notável de informação genética codificada deriva do fato de que os aminoácidos "compreendem" ele. A informação distribuída ao longo de uma cadeia de DNA é biologicamente relevante. Em linguagem de informática, os dados genéticos são dados semânticos. Para uma perspectiva clara sobre este ponto, considere a maneira em que as quatro bases A, G, C e T são dispostas no DNA. Como explicado, estas sequências são como letras em um alfabeto, e as letras podem soletrar, em código, as instruções para fazer proteínas. Uma sequência diferente de letras quase certamente seria biologicamente inútil. Apenas uma pequena fração de todas as sequências possíveis explicita uma mensagem biologicamente significativa, da mesma forma que somente certas sequências muito especiais de letras e palavras constituem um livro significativo. Outra forma de expressar isso é dizer que os genes e proteínas requerem extremamente elevados graus de especificidade em sua estrutura. Como afirmei na minha lista de propriedades no capítulo 1, os organismos vivos não são misteriosos por causa da complexidade em si, mas pela sua complexidade firmemente especificada. Para compreender plenamente como a vida surgiu da matéria inorgânica, precisamos saber não apenas como informação biológica foi concentrada, mas também como informação biologicamente útil veio a ser especificada, uma vez que o meio a partir do qual o primeiro organismo emergiu foi, presumivelmente, apenas uma mistura aleatória de blocos de construção moleculares. Em suma, como é que informações significativas surgem espontaneamente do lixo incoerente?
Comecei esta secção, sublinhando a natureza dual das biomoléculas: elas podem ser tanto hardware , formas especiais e tridimensionais, e software. O código genético mostra o quão importante é o aspecto informativo de biomoléculas. O trabalho de explicar a origem da vida vai além de encontrar uma via química plausível de uma sopa primordial. Precisamos saber, conceitualmente, como hardware simples pode dar origem a software.
Para o proponente de design, a resposta é evidente....
Este argumento por si só destrói o naturalismo. E pior que um knock out the Mike Tyson, haha.....
https://en.wikipedia.org/wiki/Genetic_code
Última edição por Admin em Sáb Jan 16, 2016 5:52 am, editado 2 vez(es)